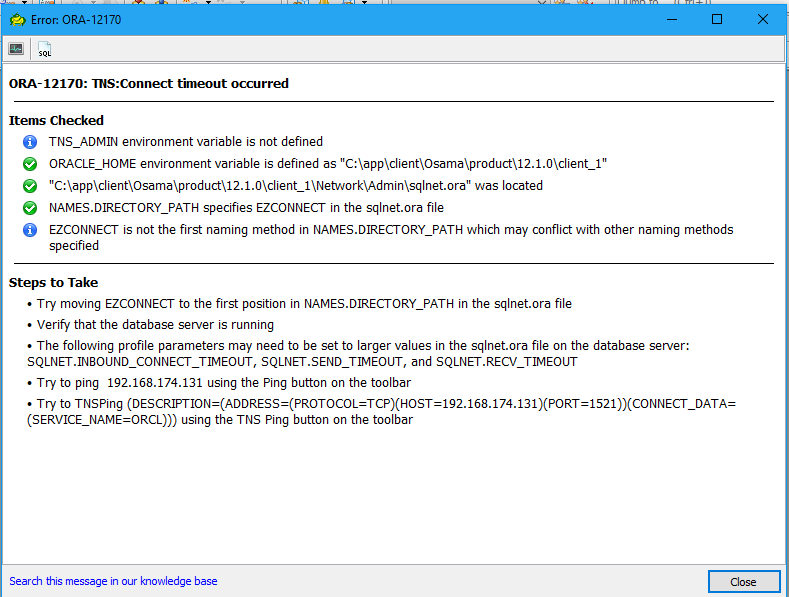
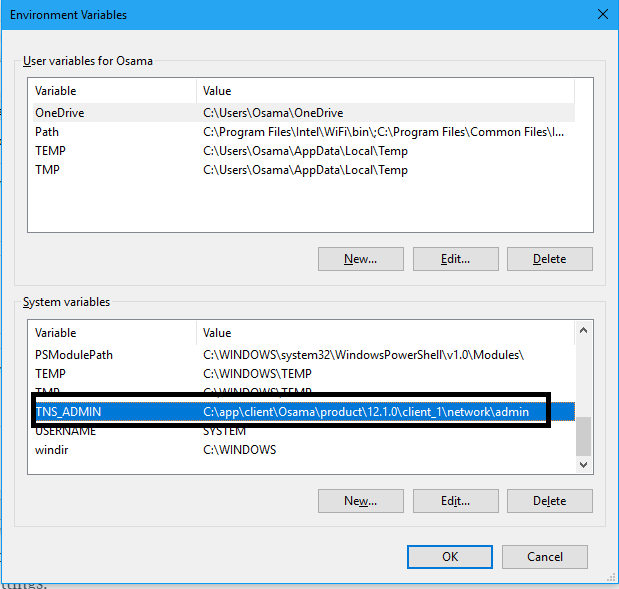
to do this oracle provide you with package called DBMS_REDEFINITION for more information about it
In this post i will show you how to partition existing table for SIEBEL application which is my case holding huge number of records.
CREATE TABLE SIEBEL.S_CASE_NEW
(
ROW_ID VARCHAR2(15 CHAR) ,
CREATED DATE DEFAULT sysdate ,
CREATED_BY VARCHAR2(15 CHAR) ,
LAST_UPD DATE DEFAULT sysdate ,
LAST_UPD_BY VARCHAR2(15 CHAR) ,
MODIFICATION_NUM NUMBER(10) DEFAULT 0 ,
CONFLICT_ID VARCHAR2(15 CHAR) DEFAULT ‘0’ ,
ASGN_USR_EXCLD_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
BU_ID VARCHAR2(15 CHAR) DEFAULT ‘0-R9NH’ ,
CASE_DT DATE ,
CASE_NUM VARCHAR2(100 CHAR) ,
CHGOFCCM_REQ_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
CLASS_CD VARCHAR2(30 CHAR) ,
LOCAL_SEQ_NUM NUMBER(10) DEFAULT 1 ,
NAME VARCHAR2(100 CHAR) ,
PR_REP_DNRM_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
PR_REP_MANL_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
PR_REP_SYS_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
STATUS_CD VARCHAR2(30 CHAR) ,
ASGN_DT DATE,
CLOSED_DT DATE,
CURR_APPR_SEQ_NUM NUMBER(10),
DB_LAST_UPD DATE,
REWARD_AMT NUMBER(22,7),
REWARD_EXCH_DATE DATE,
APPLICANT_ID VARCHAR2(15 CHAR),
APPR_TEMP_ID VARCHAR2(15 CHAR),
AUDIT_EMP_ID VARCHAR2(15 CHAR),
CATEGORY_TYPE_CD VARCHAR2(30 CHAR),
CITY VARCHAR2(50 CHAR),
COUNTRY VARCHAR2(30 CHAR),
CRIME_SUB_TYPE_CD VARCHAR2(30 CHAR),
CRIME_TYPE_CD VARCHAR2(30 CHAR),
DB_LAST_UPD_SRC VARCHAR2(50 CHAR),
DESC_TEXT VARCHAR2(2000 CHAR),
MSTR_CASE_ID VARCHAR2(15 CHAR),
ORG_GROUP_ID VARCHAR2(15 CHAR),
PAR_CASE_ID VARCHAR2(15 CHAR),
PRIORITY_TYPE_CD VARCHAR2(30 CHAR),
PR_AGENCY_ID VARCHAR2(15 CHAR),
PR_AGENT_ID VARCHAR2(15 CHAR),
PR_DISEASE_ID VARCHAR2(15 CHAR),
PR_POSTN_ID VARCHAR2(15 CHAR),
PR_PROD_INT_ID VARCHAR2(15 CHAR),
PR_PRTNR_ID VARCHAR2(15 CHAR),
PR_SGROUP_ID VARCHAR2(15 CHAR),
PR_SUBJECT_ID VARCHAR2(15 CHAR),
PR_SUSPCT_ID VARCHAR2(15 CHAR),
PS_APPL_ID VARCHAR2(15 CHAR),
REWARD_CURCY_CD VARCHAR2(20 CHAR),
SERIAL_NUM VARCHAR2(100 CHAR),
SOURCE_CD VARCHAR2(30 CHAR),
STAGE_CD VARCHAR2(30 CHAR),
STATE VARCHAR2(10 CHAR),
SUBJECT_NAME VARCHAR2(100 CHAR),
SUBJECT_PH_NUM VARCHAR2(40 CHAR),
SUB_STATUS_CD VARCHAR2(30 CHAR),
SUB_TYPE_CD VARCHAR2(30 CHAR),
TERRITORY_TYPE_CD VARCHAR2(30 CHAR),
THREAT_LVL_CD VARCHAR2(30 CHAR),
TYPE_CD VARCHAR2(30 CHAR),
X_APP_BIRTH_DATE DATE,
X_APP_BIRTH_DT_HIJRI VARCHAR2(10 CHAR),
X_APP_FATHER_NAME_A VARCHAR2(50 CHAR),
X_APP_FATHER_NAME_E VARCHAR2(50 CHAR),
X_APP_FAX VARCHAR2(15 CHAR),
X_APP_FIRST_NAME_A VARCHAR2(50 CHAR),
X_APP_FIRST_NAME_E VARCHAR2(50 CHAR),
X_APP_FULL_NAME VARCHAR2(100 CHAR),
X_APP_GENDER VARCHAR2(30 CHAR),
X_APP_GFATHER_NAME_A VARCHAR2(50 CHAR),
X_APP_GFATHER_NAME_E VARCHAR2(50 CHAR),
X_APP_LAST_NAME_A VARCHAR2(50 CHAR),
X_APP_LAST_NAME_E VARCHAR2(50 CHAR),
X_APP_MAIL VARCHAR2(50 CHAR),
X_APP_MOBILE VARCHAR2(15 CHAR),
X_APP_MOTHER_F_NAME_A VARCHAR2(50 CHAR),
X_APP_MOTHER_F_NAME_E VARCHAR2(50 CHAR),
X_APP_MOTHER_L_NAME_A VARCHAR2(50 CHAR),
X_APP_MOTHER_L_NAME_E VARCHAR2(50 CHAR),
X_APP_TYPE VARCHAR2(30 CHAR),
X_APPLICANT_CLASSIFICATION VARCHAR2(30 CHAR),
X_APPLICANT_NAT_ID_NO VARCHAR2(15 CHAR),
X_APPLICANT_TITLE VARCHAR2(30 CHAR),
X_APPLICANT_TYPE VARCHAR2(50 CHAR),
X_ATTACHMENT_FLG VARCHAR2(5 CHAR),
X_CANCEL_DESC VARCHAR2(300 CHAR),
X_CANCEL_REASON VARCHAR2(30 CHAR),
X_CASE_COPY_FLG VARCHAR2(30 CHAR),
X_CASE_HIJRI_DATE VARCHAR2(30 CHAR),
X_CHECK_EXISTS_FKG VARCHAR2(15 CHAR),
X_CHECK_EXISTS_FLG VARCHAR2(30 CHAR),
X_COMMERCIAL_NAME VARCHAR2(300 CHAR),
X_COMMERCIAL_REG_NO VARCHAR2(40 CHAR),
X_COPY_SERIAL_NUM VARCHAR2(100 CHAR),
X_CREATED_DATE_HEJRI VARCHAR2(30 CHAR),
X_CREATED_GRG VARCHAR2(30 CHAR),
X_CREATED_HIJRI VARCHAR2(10 CHAR),
X_CRED_EXP_DT_HIJRI VARCHAR2(10 CHAR),
X_CRED_EXPIRY_DATE DATE,
X_CRED_ISSUE_DATE DATE,
X_CRED_ISSUE_DT_HIJRI VARCHAR2(10 CHAR),
X_CRED_NO VARCHAR2(30 CHAR),
X_CRED_TYPE VARCHAR2(30 CHAR),
X_CRS_NO VARCHAR2(15 CHAR),
X_DLV_DATE DATE,
X_DLV_DATE_HIJRI VARCHAR2(10 CHAR),
X_DLV_USER_ID VARCHAR2(15 CHAR),
X_DOCUMENT_SORUCE VARCHAR2(30 CHAR),
X_EST_OWNERSHIP_TYPE VARCHAR2(30 CHAR),
X_EST_TYPE VARCHAR2(30 CHAR),
X_GIS_DATA_LOAD VARCHAR2(15 CHAR),
X_GIS_DATA_STATUS VARCHAR2(10 CHAR),
X_INV_TYPE VARCHAR2(30 CHAR),
X_IS_UPLOADED VARCHAR2(30 CHAR),
X_LAND_ORG_TYPE VARCHAR2(30 CHAR),
X_LAND_STATUS VARCHAR2(30 CHAR),
X_LAND_TYPE VARCHAR2(30 CHAR),
X_MUNICIPAL_NAME VARCHAR2(30 CHAR),
X_NATIONALITY VARCHAR2(30 CHAR),
X_ORG_END_REG_DATE DATE,
X_ORG_END_REG_HIJRI_DATE VARCHAR2(10 CHAR),
X_ORG_REGISTRATION_DATE DATE,
X_ORG_REGISTRATION_HIJRI_DATE VARCHAR2(10 CHAR),
X_ORGANIZATION_NAME VARCHAR2(200 CHAR),
X_ORIGINAL_ORG_ID VARCHAR2(15 CHAR),
X_PAPER_FLG CHAR(1 CHAR) DEFAULT ‘N’,
X_PAYMENT_DT DATE,
X_PAYMENT_FLAG VARCHAR2(30 CHAR),
X_PAYMENT_NO VARCHAR2(10 CHAR),
X_PR_EMP_ID VARCHAR2(15 CHAR),
X_PR_ENG_OFFICE_ID VARCHAR2(15 CHAR),
X_PROC_DESC VARCHAR2(100 CHAR),
X_PROC_FLG VARCHAR2(30 CHAR),
X_PROC_TYPE VARCHAR2(30 CHAR),
X_PROXY_ISSUE_AUTHORITY VARCHAR2(30 CHAR),
X_PROXY_NO VARCHAR2(10 CHAR),
X_QX_CRED_EXP_DT_HIJRI DATE,
X_REGISTRATION_DATE DATE,
X_REGISTRATION_HIJRI_DATE VARCHAR2(10 CHAR),
X_REGISTRATION_NO VARCHAR2(30 CHAR),
X_REJECT_DESC VARCHAR2(300 CHAR),
X_REJECT_REASON VARCHAR2(30 CHAR),
X_RELATION_TYPE VARCHAR2(30 CHAR),
X_RETURN_DATE DATE,
X_RETURN_DATE_HIJRI VARCHAR2(10 CHAR),
X_RETURN_NOTES VARCHAR2(100 CHAR),
X_RETURN_REASON VARCHAR2(30 CHAR),
X_SCHEMA_STATUS VARCHAR2(30 CHAR),
X_SECURITY_FLG VARCHAR2(30 CHAR),
X_SELECT_FLG CHAR(1 CHAR) DEFAULT ‘N’,
X_STRIPPED_FIRST_NAME VARCHAR2(50 CHAR),
X_STRIPPED_FULL_NAME VARCHAR2(200 CHAR),
X_STRIPPED_LAST_NAME VARCHAR2(50 CHAR),
X_STRIPPED_MOTHER_FIRST VARCHAR2(50 CHAR),
X_STRIPPED_MOTHER_FULLNAME VARCHAR2(50 CHAR),
X_STRIPPED_MOTHER_LASTNAME VARCHAR2(50 CHAR),
X_STRIPPED_SECOND_NAME VARCHAR2(50 CHAR),
X_STRIPPED_THIRD_NAME VARCHAR2(50 CHAR),
X_TO_BU_ID VARCHAR2(15 CHAR),
X_UPDATED_GRG VARCHAR2(30 CHAR),
X_UPDATED_HIJRI VARCHAR2(10 CHAR),
COR_TYPE VARCHAR2(30 CHAR),
CORR_CAS_CAT VARCHAR2(30 CHAR),
PRIMARY_EMPLOYEE VARCHAR2(30 CHAR),
SUBMIT_TO_STATUS VARCHAR2(15 CHAR),
X_DOCUMENT_TYPE VARCHAR2(30 CHAR),
X_SURVEYOR_NAME VARCHAR2(30 CHAR),
X_OLD_STATUS VARCHAR2(30 CHAR),
X_APPLICANT_ORG_ID VARCHAR2(15 CHAR),
X_APPLICANT_ROW_ID VARCHAR2(15 CHAR),
X_GIS_TOKEN VARCHAR2(100 CHAR),
X_NEW_PERMIT_FLG CHAR(1 CHAR) DEFAULT ‘Y’,
X_TRANSACTION_MOD VARCHAR2(30 CHAR),
X_TRANSACTION_STATUS VARCHAR2(30 CHAR),
X_CASE_CAT VARCHAR2(100 CHAR),
X_CASE_COPY_SERIAL NUMBER(10),
X_GIS_PARAMETER VARCHAR2(300 CHAR),
X_GIS_ROWIDS VARCHAR2(100 CHAR),
READING_FLAG CHAR(1 CHAR) DEFAULT ‘N’,
X_GIS_MUNICIPAL VARCHAR2(30 CHAR),
X_ORG_DELEGATE_NAME VARCHAR2(200 CHAR),
X_PR_POS_ORG_ID VARCHAR2(15 CHAR),
X_ORGANIZATION_STRIPPED_NAME VARCHAR2(200 CHAR),
X_CITIZEN_REVIEW CHAR(1 CHAR),
X_ALLOWED_USAGE VARCHAR2(50 CHAR),
X_AUTHORIZATION_DATE DATE,
X_AUTHORIZATION_HIJRI_DATE VARCHAR2(10 CHAR),
X_AUTHORIZATION_NO VARCHAR2(20 CHAR),
X_CIVIL_APPROVAL_DATE DATE,
X_CIVIL_APPROVAL_HIJRI_DATE VARCHAR2(10 CHAR),
X_CIVIL_APPROVAL_NO VARCHAR2(20 CHAR),
X_CIVIL_OFFICE VARCHAR2(25 CHAR),
X_NEW_MUNICIPAL_NAME VARCHAR2(30 CHAR),
X_OLD_MUNICIPAL_NAME VARCHAR2(30 CHAR),
X_OLD_STATUS_CD VARCHAR2(30 CHAR),
X_RESTRICT_NUM VARCHAR2(30 CHAR),
X_LAST_UPD_HIJRI VARCHAR2(10 CHAR),
X_APP_BIRTH_DATE_HIJRI VARCHAR2(10 CHAR),
X_FEES_EXCEPTION VARCHAR2(30 CHAR),
X_FINCL_NAME VARCHAR2(30 CHAR),
X_IS_OWNER VARCHAR2(15 CHAR),
X_MANAGER_ID VARCHAR2(15 CHAR),
X_OWNERSHIP_TYPE VARCHAR2(30 CHAR),
X_PRINT_FLG CHAR(1 CHAR) DEFAULT ‘N’,
X_PRNT_FLG VARCHAR2(5 CHAR),
X_SECRETARY_ID VARCHAR2(15 CHAR),
X_UNDER_SECRETARY_ID VARCHAR2(15 CHAR),
X_VIEW_SEQUENCE NUMBER(10) DEFAULT 0,
X_REGULATION_ACCPTNCE_FLG VARCHAR2(7 CHAR),
X_CONFIRM_FLAG VARCHAR2(7 CHAR),
X_OCCUPATION_IN_RESIDENCE VARCHAR2(30 CHAR),
X_ROWNUM NUMBER(10),
X_NUMBER_ARCHIVAL VARCHAR2(15 CHAR),
X_ATTACHMENT_PARAMETERS VARCHAR2(500 CHAR),
X_ATTACHMENT_ROW_IDS VARCHAR2(500 CHAR),
X_BP_ID VARCHAR2(15 CHAR),
X_CONTROL_SUB_TYPE VARCHAR2(30 CHAR),
X_CONTROL_TYPE VARCHAR2(30 CHAR),
X_DEPOSIT_ID VARCHAR2(15 CHAR),
X_MALL_ID VARCHAR2(15 CHAR),
X_NEW_DEPOSIT NUMBER(10),
X_SOURCE_ID VARCHAR2(15 CHAR),
X_STORE_ID VARCHAR2(15 CHAR),
APPEALED_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
CHANGED_FLG CHAR(1 CHAR) DEFAULT ‘N’ ,
EVAL_ASSESS_ID VARCHAR2(15 CHAR),
X_ARCHIEVING_TYPE VARCHAR2(30 CHAR),
X_ACTIVITY_ID VARCHAR2(15 CHAR),
X_OLD_SERIAL_NUM VARCHAR2(20 CHAR),
X_OWNER_ORG_POSTN_ID VARCHAR2(15 CHAR),
X_PR_CNTR_POSTN_ID VARCHAR2(15 CHAR),
X_REPORT_URL VARCHAR2(500 CHAR),
X_VIOLATION_ID VARCHAR2(15 CHAR),
X_APPLICANT_SOURCE VARCHAR2(50 CHAR)
)
PARTITION BY RANGE (created)(PARTITION S_CASE_2015 VALUES LESS THAN (TO_DATE(’01/01/2016′, ‘DD/MM/YYYY’)), PARTITION S_CASE_2016 VALUES LESS THAN (TO_DATE(’01/01/2017′, ‘DD/MM/YYYY’)), PARTITION S_CASE_2017 VALUES LESS THAN (MAXVALUE));