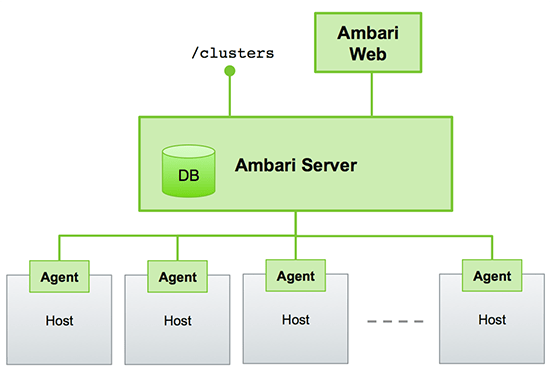
Observability is no longer optional for production Kubernetes environments. As microservices architectures grow in complexity, the ability to understand system behavior through metrics, logs, and traces becomes critical for maintaining reliability and reducing mean time to resolution (MTTR).
This article walks through deploying a complete observability stack on Kubernetes using Prometheus for metrics, Grafana for visualization, and Loki for log aggregation. We’ll cover high-availability configurations, persistent storage, alerting, and best practices for production deployments.
Prerequisites
Before starting, ensure you have:
- Kubernetes cluster (1.25+) with at least 3 worker nodes
- kubectl configured with cluster admin access
- Helm 3.x installed
- Storage class configured for persistent volumes
- Minimum 8GB RAM and 4 vCPUs per node for production workloads
Step 1: Create Dedicated Namespace
Isolate observability components in a dedicated namespace:
kubectl create namespace observability
kubectl label namespace observability \
monitoring=enabled \
pod-security.kubernetes.io/enforce=privileged
Step 2: Deploy Prometheus with High Availability
We’ll use the kube-prometheus-stack Helm chart, which includes Prometheus Operator, Alertmanager, and common exporters.
Add Helm Repository
helm repo add prometheus-community \
https://prometheus-community.github.io/helm-charts
helm repo update
Create Values File
# prometheus-values.yaml
prometheus:
prometheusSpec:
replicas: 2
retention: 30d
retentionSize: 40GB
resources:
requests:
cpu: 500m
memory: 2Gi
limits:
cpu: 2000m
memory: 8Gi
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
podAntiAffinity: hard
additionalScrapeConfigs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
alertmanager:
alertmanagerSpec:
replicas: 3
storage:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
podAntiAffinity: hard
config:
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK'
route:
group_by: ['alertname', 'namespace', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'slack-notifications'
routes:
- match:
severity: critical
receiver: 'slack-critical'
repeat_interval: 1h
- match:
severity: warning
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
send_resolved: true
title: '{{ .Status | toUpper }}: {{ .CommonLabels.alertname }}'
text: >-
{{ range .Alerts }}
*Namespace:* {{ .Labels.namespace }}
*Pod:* {{ .Labels.pod }}
*Description:* {{ .Annotations.description }}
{{ end }}
- name: 'slack-critical'
slack_configs:
- channel: '#alerts-critical'
send_resolved: true
nodeExporter:
enabled: true
kubeStateMetrics:
enabled: true
grafana:
enabled: true
replicas: 2
persistence:
enabled: true
storageClassName: gp3
size: 10Gi
adminPassword: "CHANGE_ME_SECURE_PASSWORD"
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-kube-prometheus-prometheus:9090
access: proxy
isDefault: true
- name: Loki
type: loki
url: http://loki-gateway.observability.svc.cluster.local
access: proxy
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
kubernetes-cluster:
gnetId: 7249
revision: 1
datasource: Prometheus
node-exporter:
gnetId: 1860
revision: 31
datasource: Prometheus
kubernetes-pods:
gnetId: 6417
revision: 1
datasource: Prometheus
ingress:
enabled: true
ingressClassName: nginx
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
hosts:
- grafana.example.com
tls:
- secretName: grafana-tls
hosts:
- grafana.example.com
Install Prometheus Stack
helm install prometheus prometheus-community/kube-prometheus-stack \
--namespace observability \
--values prometheus-values.yaml \
--version 55.5.0
Verify Deployment
kubectl get pods -n observability -l app.kubernetes.io/name=prometheus
kubectl get pods -n observability -l app.kubernetes.io/name=alertmanager
Step 3: Deploy Loki for Log Aggregation
Loki provides cost-effective log aggregation by indexing only metadata (labels) rather than full log content.
Create Loki Values File
# loki-values.yaml
loki:
auth_enabled: false
commonConfig:
replication_factor: 3
path_prefix: /var/loki
storage:
type: s3
bucketNames:
chunks: loki-chunks-bucket
ruler: loki-ruler-bucket
admin: loki-admin-bucket
s3:
endpoint: s3.us-east-1.amazonaws.com
region: us-east-1
secretAccessKey: ${AWS_SECRET_ACCESS_KEY}
accessKeyId: ${AWS_ACCESS_KEY_ID}
s3ForcePathStyle: false
insecure: false
schemaConfig:
configs:
- from: 2024-01-01
store: tsdb
object_store: s3
schema: v13
index:
prefix: loki_index_
period: 24h
limits_config:
retention_period: 744h # 31 days
ingestion_rate_mb: 10
ingestion_burst_size_mb: 20
max_streams_per_user: 10000
max_line_size: 256kb
compactor:
working_directory: /var/loki/compactor
shared_store: s3
compaction_interval: 10m
retention_enabled: true
retention_delete_delay: 2h
deploymentMode: Distributed
ingester:
replicas: 3
persistence:
enabled: true
size: 10Gi
storageClass: gp3
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 2000m
memory: 4Gi
distributor:
replicas: 3
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 1000m
memory: 1Gi
querier:
replicas: 3
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 2000m
memory: 4Gi
queryFrontend:
replicas: 2
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 1000m
memory: 1Gi
queryScheduler:
replicas: 2
compactor:
replicas: 1
persistence:
enabled: true
size: 10Gi
storageClass: gp3
gateway:
replicas: 2
ingress:
enabled: true
ingressClassName: nginx
hosts:
- host: loki.example.com
paths:
- path: /
pathType: Prefix
Install Loki
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install loki grafana/loki \
--namespace observability \
--values loki-values.yaml \
--version 5.41.0
Step 4: Deploy Promtail for Log Collection
Promtail runs as a DaemonSet to collect logs from all nodes and forward them to Loki.
# promtail-values.yaml
config:
clients:
- url: http://loki-gateway.observability.svc.cluster.local/loki/api/v1/push
tenant_id: default
snippets:
pipelineStages:
- cri: {}
- multiline:
firstline: '^\d{4}-\d{2}-\d{2}'
max_wait_time: 3s
- json:
expressions:
level: level
msg: msg
timestamp: timestamp
- labels:
level:
- timestamp:
source: timestamp
format: RFC3339
scrapeConfigs: |
- job_name: kubernetes-pods
pipeline_stages:
{{- toYaml .Values.config.snippets.pipelineStages | nindent 8 }}
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_controller_name
regex: ([0-9a-z-.]+?)(-[0-9a-f]{8,10})?
action: replace
target_label: __tmp_controller_name
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_name
- __meta_kubernetes_pod_label_app
- __tmp_controller_name
- __meta_kubernetes_pod_name
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: app
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_instance
- __meta_kubernetes_pod_label_instance
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: instance
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_component
- __meta_kubernetes_pod_label_component
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: component
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node_name
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: $1
separator: /
source_labels:
- namespace
- app
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- action: replace
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
- action: replace
regex: true/(.*)
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_annotationpresent_kubernetes_io_config_hash
- __meta_kubernetes_pod_annotation_kubernetes_io_config_hash
- __meta_kubernetes_pod_container_name
target_label: __path__
daemonset:
enabled: true
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
Install Promtail
helm install promtail grafana/promtail \
--namespace observability \
--values promtail-values.yaml \
--version 6.15.3
Step 5: Configure Custom Alerts
Create PrometheusRule resources for critical alerts:
# custom-alerts.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: custom-application-alerts
namespace: observability
labels:
release: prometheus
spec:
groups:
- name: application.rules
rules:
- alert: HighErrorRate
expr: |
(
sum(rate(http_requests_total{status=~"5.."}[5m])) by (namespace, service)
/
sum(rate(http_requests_total[5m])) by (namespace, service)
) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "High error rate detected"
description: "Service {{ $labels.service }} in namespace {{ $labels.namespace }} has error rate of {{ $value | humanizePercentage }}"
- alert: HighLatency
expr: |
histogram_quantile(0.95,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le, namespace, service)
) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "High latency detected"
description: "Service {{ $labels.service }} p95 latency is {{ $value | humanizeDuration }}"
- alert: PodCrashLooping
expr: |
increase(kube_pod_container_status_restarts_total[1h]) > 5
for: 10m
labels:
severity: warning
annotations:
summary: "Pod crash looping"
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} has restarted {{ $value }} times in the last hour"
- alert: PersistentVolumeUsageHigh
expr: |
(
kubelet_volume_stats_used_bytes
/
kubelet_volume_stats_capacity_bytes
) > 0.85
for: 15m
labels:
severity: warning
annotations:
summary: "PV usage high"
description: "PersistentVolume {{ $labels.persistentvolumeclaim }} is {{ $value | humanizePercentage }} full"
- name: infrastructure.rules
rules:
- alert: NodeMemoryPressure
expr: |
(
node_memory_MemAvailable_bytes
/
node_memory_MemTotal_bytes
) < 0.1
for: 5m
labels:
severity: critical
annotations:
summary: "Node memory pressure"
description: "Node {{ $labels.instance }} has only {{ $value | humanizePercentage }} memory available"
- alert: NodeDiskPressure
expr: |
(
node_filesystem_avail_bytes{mountpoint="/"}
/
node_filesystem_size_bytes{mountpoint="/"}
) < 0.1
for: 10m
labels:
severity: critical
annotations:
summary: "Node disk pressure"
description: "Node {{ $labels.instance }} has only {{ $value | humanizePercentage }} disk space available"
- alert: NodeCPUHigh
expr: |
100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 10m
labels:
severity: warning
annotations:
summary: "High CPU usage"
description: "Node {{ $labels.instance }} CPU usage is {{ $value | humanize }}%"
Apply the alerts:
kubectl apply -f custom-alerts.yaml
Step 6: Create Custom Grafana Dashboard
Create a ConfigMap with a custom dashboard for application metrics:
# application-dashboard.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: application-dashboard
namespace: observability
labels:
grafana_dashboard: "1"
data:
application-overview.json: |
{
"annotations": {
"list": []
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"id": null,
"links": [],
"liveNow": false,
"panels": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "palette-classic"
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{"color": "green", "value": null},
{"color": "yellow", "value": 0.01},
{"color": "red", "value": 0.05}
]
},
"unit": "percentunit"
}
},
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 0},
"id": 1,
"options": {
"colorMode": "value",
"graphMode": "area",
"justifyMode": "auto",
"orientation": "auto",
"reduceOptions": {
"calcs": ["lastNotNull"],
"fields": "",
"values": false
},
"textMode": "auto"
},
"targets": [
{
"expr": "sum(rate(http_requests_total{status=~\"5..\"}[5m])) / sum(rate(http_requests_total[5m]))",
"refId": "A"
}
],
"title": "Error Rate",
"type": "stat"
},
{
"datasource": {
"type": "prometheus",
"uid": "prometheus"
},
"fieldConfig": {
"defaults": {
"color": {"mode": "palette-classic"},
"unit": "reqps"
}
},
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 0},
"id": 2,
"targets": [
{
"expr": "sum(rate(http_requests_total[5m])) by (service)",
"legendFormat": "{{service}}",
"refId": "A"
}
],
"title": "Requests per Second",
"type": "timeseries"
}
],
"schemaVersion": 38,
"style": "dark",
"tags": ["application", "custom"],
"templating": {"list": []},
"time": {"from": "now-1h", "to": "now"},
"title": "Application Overview",
"uid": "app-overview"
}
Step 7: ServiceMonitor for Application Metrics
Enable Prometheus to scrape your application metrics:
# application-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: application-metrics
namespace: observability
labels:
release: prometheus
spec:
selector:
matchLabels:
monitoring: enabled
namespaceSelector:
matchNames:
- production
- staging
endpoints:
- port: metrics
interval: 30s
path: /metrics
scheme: http
Add labels to your application service:
yaml
apiVersion: v1
kind: Service
metadata:
name: api-service
namespace: production
labels:
monitoring: enabled
spec:
ports:
- name: http
port: 8080
- name: metrics
port: 9090
selector:
app: api-service
Production Best Practices
Resource Planning
| Component | Min Replicas | CPU Request | Memory Request | Storage |
|---|---|---|---|---|
| Prometheus | 2 | 500m | 2Gi | 50Gi |
| Alertmanager | 3 | 100m | 256Mi | 10Gi |
| Grafana | 2 | 250m | 512Mi | 10Gi |
| Loki Ingester | 3 | 500m | 1Gi | 10Gi |
| Loki Querier | 3 | 500m | 1Gi | – |
| Promtail | DaemonSet | 100m | 128Mi | – |
Retention Policies
# Prometheus: Balance storage cost with query needs
retention: 30d
retentionSize: 40GB
# Loki: Configure compactor for automatic cleanup
limits_config:
retention_period: 744h # 31 days
Security Hardening
# Network Policy for Prometheus
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: prometheus-network-policy
namespace: observability
spec:
podSelector:
matchLabels:
app.kubernetes.io/name: prometheus
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
monitoring: enabled
ports:
- protocol: TCP
port: 9090
egress:
- to:
- namespaceSelector: {}
ports:
- protocol: TCP
port: 9090
- protocol: TCP
port: 443