Setting up the OCI CLI (Command Line Interface) involves several steps to authenticate, configure, and start using it effectively. Here’s a detailed guide to help you set up OCI CLI.
Step 1: Prerequisites
OCI Account: Ensure you have an Oracle Cloud Infrastructure account.
Access: Make sure you have appropriate permissions to create and manage resources.
Operating System: OCI CLI supports Windows, macOS, and Linux distributions.
Step 2: Install OCI CLI
Install Python: OCI CLI requires Python 3.5 or later. Install Python if it’s not already installed:
On Linux:
sudo apt update sudo apt install python3
On macOS: Install via Homebrew:
brew install python3
On Windows: Download and install Python from python.org.
Install OCI CLI: Use pip, Python’s package installer, to install OCI CLI:
pip3 install oci-cli
Step 3: Configure OCI CLI
Generate API Signing Keys: OCI CLI uses API signing keys for authentication. If you haven’t created keys yet, generate them through the OCI Console:
Go to Identity → Users.
Select your user.
Under Resources, click on API Keys.
Generate a new key pair if none exists.
Configure OCI CLI: After installing OCI CLI, configure it with your tenancy, user details, and API key:
Open a terminal or command prompt.
Run the following command:
oci setup config
Enter a location for your config file: Choose a path where OCI CLI configuration will be stored (default is ~/.oci/config).
Enter a user OCID: Enter your user OCID (Oracle Cloud Identifier).
Enter a tenancy OCID: Enter your tenancy OCID.
Enter a region name: Choose the OCI region where your resources are located (e.g., us-ashburn-1).
Do you want to generate a new API Signing RSA key pair?: If you haven’t generated API keys, choose yes and follow the prompts.
Once configured, OCI CLI will create a configuration file (config) and a key file (oci_api_key.pem) in the specified location.
In today’s rapidly evolving digital landscape, choosing the right cloud infrastructure is crucial for organizations aiming to scale, secure, and innovate efficiently. Oracle Cloud Infrastructure (OCI) stands out as a robust platform offering a comprehensive suite of cloud services tailored for enterprise-grade performance and reliability.
1. Overview of OCI: Oracle Cloud Infrastructure (OCI) provides a highly scalable and secure cloud computing platform designed to meet the needs of both traditional enterprise workloads and modern cloud-native applications. Key components include:
Compute Services: OCI offers Virtual Machines (VMs) for general-purpose and high-performance computing, Bare Metal instances for demanding workloads, and Container Engine for Kubernetes clusters.
Storage Solutions: Includes Block Volumes for persistent storage, Object Storage for scalable and durable data storage, and File Storage for file-based workloads.
Networking Capabilities: Virtual Cloud Network (VCN) enables customizable network topologies with VPN and FastConnect for secure and high-bandwidth connectivity. Load Balancer distributes incoming traffic across multiple instances.
Database Options: Features Autonomous Database for self-driving, self-securing, and self-repairing databases, MySQL Database Service for fully managed MySQL databases, and Exadata Cloud Service for high-performance databases.
Example 2: Implementing Autonomous Database
Autonomous Database handles routine tasks like patching, backups, and updates automatically, allowing the IT team to focus on enhancing customer experiences.
Security and Compliance: OCI provides robust security features such as Identity and Access Management (IAM) for centralized control over access policies, Security Zones for isolating critical workloads, and Web Application Firewall (WAF) for protecting web applications from threats.
Management and Monitoring: OCI’s Management Tools offer comprehensive monitoring, logging, and resource management capabilities. With tools like Oracle Cloud Infrastructure Monitoring and Logging, organizations gain insights into performance metrics and operational logs, ensuring proactive management and troubleshooting.
Integration and Developer Tools: For seamless integration, OCI offers Oracle Integration Cloud and API Gateway, enabling organizations to connect applications and services securely across different environments. Developer Tools like Oracle Cloud Developer Tools and SDKs support agile development and deployment practices.
Oracle Cloud Infrastructure (OCI) emerges as a robust solution for enterprises seeking a secure, scalable, and high-performance cloud platform. Whether it’s deploying mission-critical applications, managing large-scale databases, or ensuring compliance and security, OCI offers the tools and capabilities to drive innovation and business growth.
AWS offers a wide variety of services and Partner tools to help you migrate your data sets, whether they are files, databases, machine images, block volumes, or even tape backups.
AWS Storage Gateway
AWS Storage Gateway is a service that gives your applications seamless and secure integration between on-premises environments and AWS storage.
It provides you low-latency access to cloud data with a Storage Gateway appliance.
Storage Gateway types
Choose a Storage Gateway type that is the best fit for your workload.
Amazon s3 file Gateway
Amazon FSx file Gateway
Tape Gateway
Volume Gateway
The Storage Gateway Appliance supports the following protocols to connect to your local data:
NFS or SMB for files
iSCSI for volumes
iSCSI VTL for tapes
Your storage gateway appliance runs in one of four modes: Amazon S3 File Gateway, Amazon FSx File Gateway, Tape Gateway, or Volume Gateway.
Data moved to AWS using Storage Gateway can be sent to the following destinations through the Storage Gateway managed service:
Amazon FSx for Windows File Server (Amazon FSx File Gateway)
Amazon EBS (Volume Gateway)
AWS Datasync
Manual tasks related to data transfers can slow down migrations and burden IT operations. DataSync facilitates moving large amounts of data between on-premises storage and Amazon S3 and Amazon EFS, or FSx for Windows File Server. By default, data is encrypted in transit using Transport Layer Security (TLS) 1.2. DataSync automatically handles scripting copy jobs, scheduling and monitoring transfers, validating data, and optimizing network usage.
Reduce on-premises storage infrastructure by shifting SMB-based data stores and content repositories from file servers and NAS arrays to Amazon S3 and Amazon EFS for analytics.
DataSync deploys as a single software agent that can connect to multiple shared file systems and run multiple tasks. The software agent is typically deployed on premises through a virtual machine to handle the transfer of data over the wide area network (WAN) to AWS. On the AWS side, the agent connects to the DataSync service infrastructure. Because DataSync is a service, there is no infrastructure for customers to set up or maintain in the cloud. DataSync configuration is managed directly from the console.
AWS Snow Family service models
The AWS Snow Family helps customers that need to run operations in austere, non-data center environments and in locations where there’s lack of consistent network connectivity. The AWS Snow Family, comprised of AWS Snowcone, AWS Snowball, and AWS Snowmobile, offers several physical devices and capacity points.
There are three types of cloud storage: object, file, and block. Each storage option has a unique combination of performance, durability, cost, and interface.
Block storage – Enterprise applications like databases or enterprise resource planning (ERP) systems often require dedicated, low-latency storage for each host. This is similar to direct-attached storage (DAS) or a Storage Area Network (SAN). Block-based cloud storage solutions like Amazon Elastic Block Store (Amazon EBS) are provisioned with each virtual server and offer the ultra-low latency required for high-performance workloads.
File storage – Many applications must access shared files and require a file system. This type of storage is often supported with a Network Attached Storage (NAS) server. File storage solutions like Amazon Elastic File System (Amazon EFS) are ideal for use cases such as large content repositories, development environments, media stores, or user home directories.
Object storage – Applications developed in the cloud need the vast scalability and metadata of object storage. Object storage solutions like Amazon Simple Storage Service (Amazon S3) are ideal for building modern applications. Amazon S3 provides scale and flexibility. You can use it to import existing data stores for analytics, backup, or archive.
AWS provides you with services for your block, file and object storage needs. Select each hotspot in the image to see what services are available for you to explore to build solutions.
Amazon S3 use cases
Backup and restore.
Data Lake for analytics.
Media storage
Static website.
Archiving
Buckets and objects
Amazon S3 stores data as objects within buckets. An object is composed of a file and any metadata that describes that file. The diagram below contains a URL comprised of a bucket and an object key. The object key is the unique identifier of an object in a bucket. The combination of a bucket, key, and version ID uniquely identifies each object. The object is uniquely addressed through the combination of the web service endpoint, bucket name, key, and optionally, a version.
To store an object in Amazon S3, upload the file into a bucket. When you upload a file, you can set permissions on the object and add metadata. You can have one or more buckets in your account. For each bucket, you control who can create, delete, and list objects in the bucket.
Amazon S3 access control
By default, all Amazon S3 resources—buckets, objects, and related resources (for example, lifecycle configuration and website configuration)—are private. Only the resource owner, an AWS account that created it, can access the resource. The resource owner can grant access permissions to others by writing access policies.
AWS provides several different tools to help developers configure buckets for a wide variety of workloads.
Most Amazon S3 use cases do not require public access.
Amazon S3 usually stores data from other applications. Public access is not recommended for these types of buckets.
Amazon S3 includes a block public access feature. This acts as an additional layer of protection to prevent accidental exposure of customer data.
Amazon S3 Event Notifications
Amazon S3 event notifications enable you to receive notifications when certain object events happen in your bucket. Here is an example of an event notification workflow to convert images to thumbnails. To learn more, select each of the three hotspots in the diagram below.
Amazon S3 cost factors and best practices
Cost is an important part of choosing the right Amazon S3 storage solution. Some of the Amazon S3 cost factors to consider include the following:
Storage – Per-gigabyte cost to hold your objects. You pay for storing objects in your S3 buckets. The rate you’re charged depends on your objects’ size, how long you stored the objects during the month, and the storage class. There are per-request ingest charges when using PUT, COPY, or lifecycle rules to move data into any S3 storage class.
Requests and retrievals – The number of API calls: PUT and GET requests. You pay for requests made against your S3 buckets and objects. S3 request costs are based on the request type, and are charged on the quantity of requests. When you use the Amazon S3 console to browse your storage, you incur charges for GET, LIST, and other requests that are made to facilitate browsing.
Data transfer – Usually no transfer fee for data-in from the internet and, depending on the requestor location and medium of data transfer, different charges for data-out.
Management and analytics – You pay for the storage management features and analytics that are enabled on your account’s buckets. These features are not discussed in detail in this course.
S3 Replication and S3 Versioning can have a big impact on your AWS bill. These services both create multiple copies of your objects and you pay for each PUT request in addition to the storage tier charge. S3 Cross-Region Replication also requires data transfer between AWS Regions.
Shared file systems
Using a fully managed cloud shared file system solution removes complexities, reduces costs, and simplifies management. To learn more about shared file systems, select each hotspot in the image below.
Amazon Elastic File System (EFS)
Amazon EFS provides a scalable, elastic file system for Linux-based workloads for use with AWS Cloud services and on-premises resources.
You’re able to access your file system across Availability Zones, AWS Regions, and VPCs while sharing files between thousands of EC2 instances and on-premises servers through AWS Direct Connect or AWS VPN.
You can create a file system, mount the file system on an Amazon EC2 instance, and then read and write data to and from your file system.
Amazon EFS provides a shared, persistent layer that allows stateful applications to elastically scale up and down. Examples include DevOps, web serving, web content systems, media processing, machine learning, analytics, search index, and stateful microservices applications. Amazon EFS can support a petabyte-scale file system, and the throughput of the file system also scales with the capacity of the file system.
Because Amazon EFS is serverless, you don’t need to provision or manage the infrastructure or capacity. Amazon EFS file systems can be shared with up to tens of thousands of concurrent clients, no matter the type. These could be traditional EC2 instances, containers running in one of your self-managed clusters or in one of the AWS container services, Amazon ECS, Amazon EKS, and Fargate, or in a serverless function running in Lambda.
Use Amazon EFS to lower your total cost of ownership for shared file storage. Choose Amazon EFS One Zone for data that does not require replication across multiple Availability Zones and save on storage costs. Amazon EFS Standard-Infrequent Access (EFS Standard-IA) and Amazon EFS One Zone-Infrequent Access (EFS One Zone-IA) are storage classes that provide price/performance that is cost-optimized for files not accessed every day.
Use Amazon EFS scaling and automation to save on management costs, and pay only for what you use.
Amazon FSx
With Amazon FSx, you can quickly launch and run feature-rich and high-performing file systems. The service provides you with four file systems to choose from. This choice is based on your familiarity with a given file system or by matching the feature sets, performance profiles, and data management capabilities to your needs.
Amazon FSx for Windows File Server
FSx for Windows File Server provides fully managed Microsoft Windows file servers that are backed by a native Windows file system. Built on Windows Server, Amazon FSx delivers a wide range of administrative features such as data deduplication, end-user file restore, and Microsoft Active Directory.
Amazon FSx for Lustre (FSx for Lustre)
FSx for Lustre is a fully managed service that provides high-performance, cost-effective storage. FSx for Lustre is compatible with the most popular Linux-based AMIs, including Amazon Linux, Amazon Linux 2, Red Hat Enterprise Linux (RHEL), CentOS, SUSE Linux, and Ubuntu.
Amazon FSx for NETapp ONTAP
FSx for NETapp ONTAP provides fully managed shared storage in the AWS Cloud with the popular data access and management capabilities of ONTAP.
Amazon FSx for OpenZFS
Where the road leads, I will go. Along the stark desert, across the wide plains, into the deep forests I will follow the call of the world and embrace its ferocious beauty.
Disaster recovery (DR) is about preparing for and recovering from any event that has a negative impact on a company’s business continuity or finances. This includes hardware or software failure, a network outage, a power outage, physical damage to a building, human error, or natural disasters.
To minimize the impact of a disaster, companies invest time and resources to plan and prepare, train employees, and document and update processes. Companies that have traditional environments duplicate their infrastructure to ensure the availability of spare capacity. The infrastructure is under-utilized or over-provisioned during normal operations. AWS gives you the flexibility to optimize resources during a DR event, which can result in significant cost savings.
Disaster recovery plan failure
Not all Disaster Recovery (DR) plans are created equal, and many fail. Testing, resources, and planning are vital components of a successful DR plan.
Testing – Test your DR plan to validate the implementation. Regularly test failover to your workload’s DR Region to ensure that you are meeting recovery objectives. Avoid developing recovery paths that you rarely run.
22Resources – Regularly run your recovery path in production. This will validate the recovery path and help you verify that resources are sufficient for operation throughout the event.
33Planning – The only recovery that works is the path you test frequently. The capacity of the secondary resources, which might have been sufficient when you last tested, may no longer be able to tolerate your load. This is why it is best to have a small number of recovery paths. Establish recovery patterns and regularly test them.
Failover and Regions
AWS is available in multiple Regions around the globe. You can choose the most appropriate location for your DR site, in addition to the site where your system is fully deployed. It is highly unlikely for a Region to be unavailable. But it is possible if a very large-scale event impacts a Region—for instance, a natural disaster.
AWS maintains a page that inventories current products and services offered by Region. AWS maintains a strict Region isolation policy so that any large-scale event in one Region will not impact any other Region. We encourage our customers to take a similar multi-Region approach to their strategy. Each Region should be able to be taken offline with no impact to any other Region.
Recovery point objective (RPO) and Recovery time objective (RTO)
RECOVERY POINT OBJECTIVE (RPO)
Recovery Point Objective (RPO) is the acceptable amount of data loss measured in time.
For example, if a disaster occurs at 1:00 p.m. (13:00) and the RPO is 12 hours, the system should recover all data that was in the system before 1:00 a.m. (01:00) that day. Data loss will, at most, span 12 hours—between 1:00 p.m. and 1:00 a.m.
RECOVERY TIME OBJECTIVE (RTO)
Recovery Time Objective (RTO) is the time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA).
For example, if a disaster occurs at 1:00 p.m. (13:00) and the RTO is 1 hour, the DR process should restore the business process to the acceptable service level by 2:00 p.m. (14:00).
A company typically decides on an acceptable RPO and RTO based on the financial impact to the business when systems are unavailable. The company determines financial impact by considering many factors, such as the loss of business and damage to its reputation due to downtime and the lack of systems availability.
IT organizations plan solutions to provide cost-effective system recovery based on the RPO within the timeline and the service level established by the RTO.
Essential AWS services and features for DR
Before discussing the various approaches to DR, it is important to review the AWS services and features that are the most relevant to it. This section provides a summary.
When planning for DR, it is important to consider the services and features that support data migration and durable storage. For some of the scenarios that involve either a scaled-down or a fully scaled deployment of your system in AWS, compute resources will be required as well.
During a disaster, you need to either provision new resources or fail over to existing preconfigured resources. These resources include code and content. But they can also include other pieces, such as Domain Name System (DNS) entries, network firewall rules, and virtual machines or instances. To learn more about the essential AWS services and features for DR.
AWS Backup
AWS Backup is a fully managed backup service that makes it easy to centralize and automate the backup of data across AWS services. AWS Backup also helps customers support their regulatory compliance obligations and meet business continuity goals.
AWS Backup works with AWS Organizations. It centrally deploys data protection policies to configure, manage, and govern your backup activity. It works across your AWS accounts and resources. This includes Amazon EC2 instances and Amazon EBS volumes. You can backup databases such as DynamoDB tables, Amazon DocumentDB and Amazon Neptune graph databases, and Amazon RDS databases, including Aurora database clusters. You can also backup Amazon EFS, Amazon S3, Storage Gateway volumes, and all versions of Amazon FSx, including FSx for Lustre and FSx for Windows File Server.
Backup and restore example
In most traditional environments, data is backed up to tape and sent offsite regularly. If you use this method, it can take a long time to restore your system in the event of a disruption. Amazon S3 is an ideal destination for quick access to your backup. Transferring data to and from Amazon S3 is typically done through the network and is therefore accessible from any location. You can also use a lifecycle policy to move older backups to progressively more cost efficient storage classes over time.
If the remote server fails, you can restore services by deploying a disaster recovery VPC. Use CloudFormation to automate deployment of core networking. Create an EC2 instance using an AMI that matched your remote server. Then restore your systems by retrieving your backups from Amazon S3. You then adjust DNS records to point to AWS.
Disaster Recovery (DR) Architectures on AWS
Review the section below to learn more about the pilot light, low-capacity standby, and multi-site active-active disaster recovery architectures.
Pilot Light
With the pilot light approach, you replicate your data from one environment to another and provision a copy of your core workload infrastructure.
PILOT LIGHT RECOVERY
When disaster strikes, the servers in the recovery environment start up and then Route 53 begins sending them production traffic. The essential infrastructure pieces include DNS, networking features, and various Amazon EC2 features.
Low-capacity standby
Low-capacity standby is similar to pilot light. The warm standby approach involves creating a scaled down, but fully functional, copy of your production environment in a recovery environment. By identifying your business-critical systems, you can fully duplicate these systems on AWS and have them always on. This decreases the time to recovery because you do not have to wait for resources in the recovery environment to start up.
If the production environment is unavailable, Route 53 switches over to the recovery environment, which automatically scales its capacity out in the event of a failover from the primary system.
For your critical loads, fully working low-capacity standby RTO is as long as it takes to fail over. For all other loads, it takes as long as it takes you to scale up. The RPO depends on the replication type.
When disaster strikes, the servers in the recovery environment start up and then Route 53 begins sending them production traffic. The essential infrastructure pieces include DNS, networking features, and various Amazon EC2 features.
Multi-site active-active
In a disaster situation in Production A, you can adjust the DNS weighting and send all traffic to the Production B environment. The capacity of the AWS service can be rapidly increased to handle the full production load. You can use Amazon EC2 Auto Scaling to automate this process. You might need some application logic to detect the failure of the primary database services and cut over to the parallel database services running in AWS.
This pattern potentially has the least downtime of all. It has more costs associated with it, because more systems are running. The cost of this scenario is determined by how much production traffic is handled by AWS during normal operation. In the recovery phase, you pay only for what you use for the duration that the DR environment is required at full scale. To further reduce cost, purchase Amazon EC2 Reserved Instances for AWS servers that must be always on.
In this post, I will share a Terraform script I developed and uploaded to my GitHub repository, aimed at simplifying and automating the creation of IAM users in AWS. This tool is not just about saving time; it’s about enhancing security, ensuring consistency, and enabling scalability in managing user access to AWS services.
For those who may be new to Terraform, it’s a powerful tool that allows you to build, change, and version infrastructure safely and efficiently. Terraform can manage existing service providers as well as custom in-house solutions. The code I’m about to share represents a practical application of Terraform’s capabilities in the AWS ecosystem.
Whether you are an experienced DevOps professional, a system administrator, or just someone interested in cloud infrastructure management, this post is designed to provide you with valuable insights into automating IAM user creation. Let’s dive into how this Terraform script can streamline your AWS IAM processes, ensuring a more secure and efficient cloud environment.
Welcome to our deep dive into the world of containerization and cloud orchestration! In this blog post, we’re going to explore the innovative realm of AWS ECS Fargate, a game-changer in the world of container management and deployment. AWS ECS Fargate simplifies the process of running containers by eliminating the need to manage servers or clusters, offering a more streamlined and efficient way to deploy your applications.
But that’s not all. We understand the importance of infrastructure as code (IaC) in today’s fast-paced tech environment. That’s why we’re also providing you with a powerful resource – a GitHub repository containing Terraform code, meticulously crafted to help you deploy AWS ECS Fargate services with ease. Terraform, an open-source infrastructure as code software tool, enables you to define and provision a datacenter infrastructure using a declarative configuration language. This integration with Terraform not only automates your deployments but also ensures consistency and reliability in your infrastructure setup.
Whether you’re new to AWS ECS Fargate or looking to enhance your existing knowledge, this post aims to provide you with actionable insights and practical know-how. From setting up your first Fargate service to scaling and managing it effectively, we’ve got you covered. So, gear up as we embark on this journey to harness the full potential of AWS ECS Fargate, supplemented by the power of Terraform automation.
Stay tuned, and don’t forget to check out our GitHub repository linked at the end of this post for the Terraform code that will be your ally in deploying and managing your Fargate services efficiently.
Access keys are long-term credentials for an IAM user or the AWS account root user. You can use access keys to sign programmatic requests to the AWS CLI or AWS API (directly or using the AWS SDK).
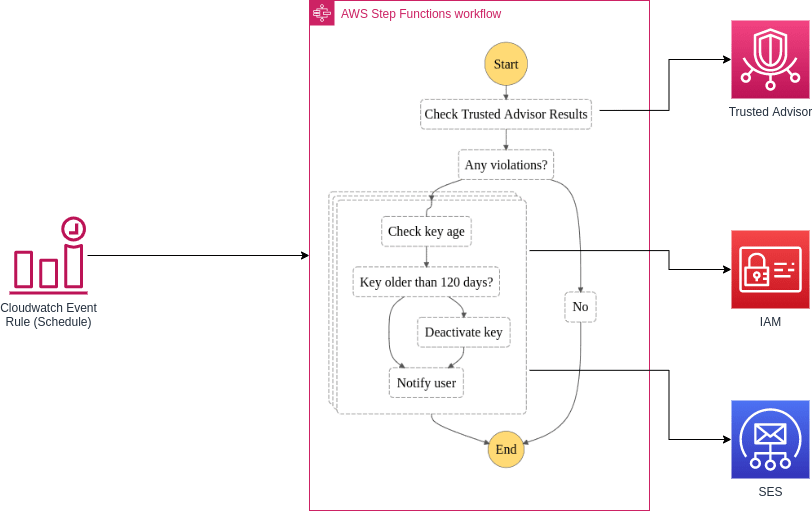
But for security reason this key should be changed from while to while, therefore this soltuion will provide yuo an automation way to remind the users.
This solution deploys a step functions workflow that is designed to detect user IAM access keys that are older than 90 days. It will send out an email notification to the affected user every day until it is resolved. For access keys older than 120 days, the key will be deactivated.
AWS edge computing services provide infrastructure and software that move data processing and analysis as close to the endpoint as necessary. This includes deploying AWS managed hardware and software to locations outside AWS data centers, and even onto customer-owned devices.
You can extend the cloud for a consistent hybrid experience using these AWS edge services related to locations:
AWS edge locations – Edge locations are connected to the AWS Regions through the AWS network backbone. Amazon CloudFront, AWS WAF, and AWS Shield are services you use here.
AWS Local Zones – Local Zones are an extension of the AWS Cloud located close to large population and industry centers. You learned about Local Zones in Module 1: Architecting Fundamentals.
AWS Outposts – With AWS Outposts, you can run some AWS services on premises or at your own data center.
AWS Snow Family – The Snow Family of products provides offline storage at the edge, which is used to deliver data back to AWS Regions.
Edge services architecture
Review the edge services architecture. A user sends a request to an application partly hosted on premises. The user’s request interacts with Amazon Route 53, AWS WAF, Amazon CloudFront and AWS Outposts. The AWS services hosted in the cloud are protected with AWS Shield.
Amazon Route 53
Amazon Route 53 provides a DNS, domain name registration, and health-checks. Route 53 was designed to give developers and businesses a reliable and cost-effective way to route end users to internet applications. It translates names like example.com into the numeric IP addresses that computers use to connect to each other.
Route 53 effectively connects user requests to infrastructure running in AWS—such as EC2 instances, ELB load balancers, or Amazon S3 buckets—and can also be used to route users to infrastructure outside of AWS.
You can configure a Amazon CloudWatch alarm to check on the state of your endpoints. Combine your DNS with Health Check Metrics to monitor and route traffic to healthy endpoints.
Amazon Route 53 public and private DNS
A hosted zone is a container for records. Records contain information about how you want to route traffic for a specific domain, such as example.com, and its subdomains such as dev.example.com or mail.example.com. A hosted zone and the corresponding domain have the same name.
PUBLIC HOSTED ZONE
Public hosted zones contain records that specify how you want to route traffic on the internet.
For internet name resolution
Delegation set – for authoritative name servers to be provided to the registrar or parent domain
Route to internet-facing resources
Resolve from the internet
Global routing policies
PRIVATE HOSTED ZONE
Private hosted zones contain records that specify how you want to route traffic in your Amazon VPC.
For name resolution inside a VPC
Can be associated with multiple VPCs and across accounts
Route to VPC resources
Resolve from inside the VPC
Integrate with on-premises private zones using forwarding rules and endpoints
Routing policies
When you create a record, you choose a routing policy, which determines how Amazon Route 53 responds to queries.
Failover routing
Amazon Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources.
Each health check that you create can monitor one of the following:
The health of a specified resource, such as a web server
The status of other health checks
The status of an Amazon CloudWatch alarm
After you create a health check, you can get the status of the health check, get notifications when the status changes, and configure DNS failover.
Geolocation routing
Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from. For example, you might want all queries from Europe to be routed to an ELB load balancer in the Frankfurt Region.
Geoproximity routing
Geoproximity routing lets Amazon Route 53 route traffic to your resources based on the geographic location of your users and your resources. You can also optionally choose to route more traffic or less to a given resource by specifying a value, known as a bias. A bias expands or shrinks the size of the geographic Region from which traffic is routed to a resource.
Latency-based routing
If your application is hosted in multiple AWS Regions, you can improve performance for your users by serving their requests from the AWS Region that provides the lowest latency.
Data about the latency between users and your resources is based entirely on traffic between users and AWS data centers. If you aren’t using resources in an AWS Region, the actual latency between your users and your resources can vary significantly from AWS latency data. This is true even if your resources are located in the same city as an AWS Region.
Multivalue answer routing
Multivalue answer routing lets you configure Route 53 to return multiple values, such as IP addresses for your web servers, in response to DNS queries. You can specify multiple values for almost any record, but multivalue answer routing also lets you check the health of each resource. Route 53 returns only values for healthy resources.
The ability to return multiple health-checkable IP addresses is a way for you to use DNS to improve availability and load balancing. However, it is not a substitute for a load balancer.
Weighted routing
Weighted routing enables you to assign weights to a resource record set to specify the frequency with which different responses are served.
In this example of a blue/green deployment, a weighted routing policy is used to send a small amount of traffic to a new production environment. If the new environment is operating as intended, the amount of weighted traffic can be increased to confirm it can handle the increased load. If the test is successful, all traffic can be sent to the new environment.
Amazon CloudFront
Content delivery networks
It’s not always possible to replicate your entire infrastructure across the globe when your web traffic is geo-dispersed. It is also not cost effective. With a content delivery network (CDN), you can use its global network of edge locations to deliver a cached copy of your web content to your customers.
To reduce response time, the CDN uses the nearest edge location to the customer or the originating request location. Using the nearest edge location dramatically increases throughput because the web assets are delivered from cache. For dynamic data, you can configure many CDNs to retrieve data from the origin servers.
Use Regional edge caches when you have content that is not accessed frequently enough to remain in an edge location. Regional edge caches absorb this content and provide an alternative to having to retrieve that content from the origin server.
Edge caching
Edge caching helps applications perform dramatically faster and cost significantly less at scale. Review the content below to learn the benefits of edge caching.
WITHOUT EDGE CACHING
As an example, let’s say you are serving an image from a traditional web server, not from Amazon CloudFront. You might serve an image named sunsetphoto.png using the URL:
Your users can easily navigate to this URL and see the image. They don’t realize that their request was routed from one network to another (through the complex collection of interconnected networks that comprise the internet) until the image was found.
WITH EDGE CACHING
Amazon CloudFront speeds up the distribution of your content by routing each user request through the AWS backbone network to the edge location that can best serve your content. Typically, this is a CloudFront edge server that provides the fastest delivery to the viewer.
Using the AWS network can dramatically reduce the number of networks your users’ requests must pass through, which improves performance. Users get lower latency (the time it takes to load the first byte of the file) and higher data transfer rates.
You also get increased reliability and availability because copies of your files (also called objects) are now held (or cached) in multiple edge locations around the world.
Amazon CloudFront
Amazon CloudFront is a global CDN service that accelerates delivery of your websites, APIs, video content, or other web assets. It integrates with other AWS products to give developers and businesses a straightforward way to accelerate content to end users. There are no minimum usage commitments.
Amazon CloudFront provides extensive flexibility for optimizing cache behavior, coupled with network-layer optimizations for latency and throughput. The CDN offers a multi-tier cache by default, with regional edge caches that improve latency and lower the load on your origin servers when the object is not already cached at the edge.
Amazon CloudFront supports real-time, bidirectional communication over the WebSocket protocol. This persistent connection permits clients and servers to send real-time data to one another without the overhead of repeatedly opening connections. This is especially useful for communications applications such as chat, collaboration, gaming, and financial trading.
Support for WebSockets in Amazon CloudFront makes it possible for customers to manage WebSocket traffic through the same avenues as any other dynamic and static content. With CloudFront, customers can take advantage of distributed denial of service (DDoS) protection using the built-in CloudFront integrations with Shield and AWS WAF.
Amazon CloudFront caching
When a user requests content that you are serving with Amazon CloudFront, the user is routed to the edge location that provides the lowest latency. Content is delivered with the best possible performance. To review the steps for CloudFront caching, select each hotspot in the image below.
Improving CloudFront performance
WHAT AWS DOES
AWS provides features that improve the performance of your content delivery:
TCP optimization – CloudFront uses TCP optimization to observe how fast a network is already delivering your traffic and the latency of your current round trips. It then uses that data as input to automatically improve performance.
TLS 1.3 support – CloudFront supports TLS 1.3, which provides better performance with a simpler handshake process that requires fewer round trips. It also adds improved security features.
Dynamic content placement – Serve dynamic content, such as web applications or APIs from ELB load balancers or Amazon EC2 instances, by using CloudFront. You can improve the performance, availability, and security of your content.
You can also adjust the configuration of your CloudFront distribution to accommodate for better performance:
Define your caching strategy – Choosing an appropriate TTL is important. In addition, consider caching based on things like query string parameters, cookies, or request headers.
Improve your cache hit ratio – You can view the percentage of viewer requests that are hits, misses, and errors in the CloudFront console. Make changes to your distribution based on statistics collected in the CloudFront cache statistics report.
Use Origin Shield – Get an additional layer of caching between the regional edge caches and your origin. It is not always a best fit for your use case, but it can be beneficial for viewers that are spread across geographic regions or on-premises origins with capacity or bandwidth constraints.
DDoS Protection
A DDoS attack is an attack in which multiple compromised systems attempt to flood a target, such as a network or web application, with traffic. A DDoS attack can prevent legitimate users from accessing a service and can cause the system to crash due to the overwhelming traffic volume.
OSI layer attacks
In general, DDoS attacks can be segregated by which layer of the OSI model they attack. They are most common at the Network (layer 3), Transport (Layer 4), Presentation (Layer 6) and Application (Layer 7) Layers.
Infrastructure Layer Attacks – Attacks at Layer 3 and 4, are typically categorized as Infrastructure layer attacks. These are also the most common type of DDoS attack and include vectors like synchronized (SYN) floods and other reflection attacks like User Datagram Packet (UDP) floods. These attacks are usually large in volume and aim to overload the capacity of the network or the application servers. But fortunately, these are also the type of attacks that have clear signatures and are easier to detect.
Application Layer Attacks – An attacker may target the application itself by using a layer 7 or application layer attack. In these attacks, similar to SYN flood infrastructure attacks, the attacker attempts to overload specific functions of an application to make the application unavailable or extremely unresponsive to legitimate users.
AWS Solutions
AWS Shield Standard, AWS Web Application Firewall (WAF), and AWS Firewall Manager are AWS services that protect architectures against web-based attacks. Review the section below to learn more about each of these AWS services.
AWS Shield
AWS Shield is a managed DDoS protection service that safeguards your applications running on AWS. It provides you with dynamic detection and automatic inline mitigations that minimize application downtime and latency. There are two tiers of AWS Shield: Shield Standard and Shield Advanced.
AWS Shield Standard provides you protection against some of the most common and frequently occurring infrastructure (Layer 3 and 4) attacks. This includes SYN/UDP floods and reflection attacks. Shield Standard improves availability of your applications on AWS. The service applies a combination of traffic signatures, anomaly algorithms, and other analysis techniques. Shield Standard detects malicious traffic and it provides real-time issue mitigation. You are protected by Shield Standard at no additional charge.
If you need even more protection from DDoS attacks on your applications, consider using Shield Advanced. You get additional detection and mitigation against large and sophisticated DDoS attacks, near real-time visibility, and integration with AWS WAF, a web application firewall.
AWS Web Application Firewall (WAF)
AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits and bots. AWS WAF gives you control over how traffic reaches your applications. Create security rules that control bot traffic and block common attack patterns, such as SQL injection (SQLi) or cross-site scripting (XSS). You can also monitor HTTP(S) requests that are forwarded to your compatible AWS services.
AWS WAF: Components of access control
Before configuring AWS WAF, you should understand the components used to control access to your AWS resources.
Web ACLs – You use a web ACL to protect a set of AWS resources. You create a web ACL and define its protection strategy by adding rules.
Rules – Each rule contains a statement that defines the inspection criteria and an action to take if a web request meets the criteria.
Rules groups – You can use rules individually or in reusable rule groups.
Rule statements – This is the part of a rule that tells AWS WAF how to inspect a web request.
IP set – This is a collection of IP addresses and IP address ranges that you want to use together in a rule statement.
Regex pattern set – This is a collection of regular expressions that you want to use together in a rule statement.
AWS Firewall Manager
AWS Firewall Manager simplifies your AWS WAF and Amazon VPC security groups administration and maintenance tasks. Set up your AWS WAF firewall rules, Shield protections, and Amazon VPC security groups once.
The service automatically applies the rules and protections across your accounts and resources, even as you add new resources. Firewall Manager helps you to:
Simplify management of rules across accounts and application.
Automatically discover new accounts and remediate noncompliant events.
Deploy AWS WAF rules from AWS Marketplace.
Enable rapid response to attacks across all accounts.
As new applications are created, Firewall Manager also facilitates bringing new applications and resources into compliance with a common set of security rules from day one. Now you have a single service to build firewall rules, create security policies, and enforce them in a consistent, hierarchical manner across your entire AWS infrastructure.
AWS Outposts solutions
These applications might need to generate near-real-time responses to end-user applications, or they might need to communicate with other on-premises systems or control on-site equipment. Examples include workloads running on factory floors for automated operations in manufacturing, real-time patient diagnosis or medical imaging, and content and media streaming.
You need a solution to securely store and process customer data that must remain on premises or in countries outside an AWS Region. You need to run data-intensive workloads and process data locally, or when you want closer controls on data analysis, backup, and restore.
With Outposts, you can extend the AWS Cloud to an on-premises data center. Outposts come in different form factors, each with separate requirements. Verify that your site meets the requirements for the form factor that you’re ordering.
The AWS Outposts family is made up of two types of Outposts: Outposts racks and Outposts servers. Choose each tab to learn more about the Outposts family products.
OUTPOSTS RACKS
When you order an Outposts rack, you can choose from a variety of Outposts configurations. Each configuration provides a mix of EC2 instance types and Amazon Elastic Block Store (Amazon EBS) volumes.
The benefits of Outposts racks include the following:
Scale up to 96 42U–standard racks.
Pool compute and storage capacity between multiple Outposts racks.
Get more service options than Outposts servers.
To fulfill the Outposts rack order, AWS will schedule a date and time with you. You will also receive a checklist of items to verify or provide before the installation. The team will roll the rack to the identified position, and your electrician can power the rack. The team will establish network connectivity for the rack over the uplink that you provide, and they will configure the rack’s capacity.
The installation is complete when you confirm that the Amazon EC2 and Amazon EBS capacity for your AWS Outpost is available from your AWS account.
OUTPOSTS SERVERS
With Outposts servers, you can order hardware at a smaller scale while still providing you AWS services on premises. You can choose from Arm-based or Intel-based options. Not all services available in Outposts racks are supported in Outposts servers.
Outposts servers are delivered directly to you and installed by either your own onsite personnel or a third-party vendor. Once connected to your network, AWS will remotely provision compute and storage resources.
Benefits of Outposts servers include the following:
Place in your own rack
Choose from:
1U Graviton-based processor
2U Intel Xeon Scalable processor
Outposts extend your VPC
A virtual private cloud (VPC) spans all Availability Zones in its AWS Region. You can extend any VPC in the Region to your Outpost by adding an Outpost subnet.
Outposts support multiple subnets. You choose the EC2 instance subnet when you launch the EC2 instance in your Outpost. You cannot choose the underlying hardware where the instance is deployed, because the Outpost is a pool of AWS compute and storage capacity.
Each Outpost can support multiple VPCs that can have one or more Outpost subnets.
You create Outpost subnets from the VPC CIDR range where you created the Outpost. You can use the Outpost address ranges for resources, such as EC2 instances that reside in the Outpost subnet. AWS does not directly advertise the VPC CIDR, or the Outpost subnet range to your on-premises location.



{kind=link}