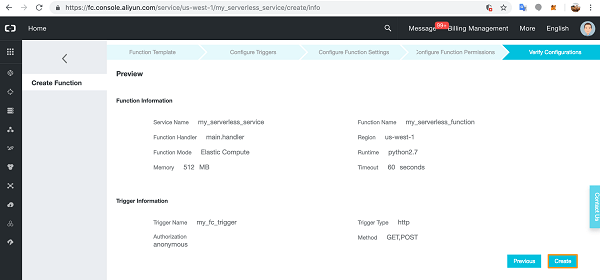
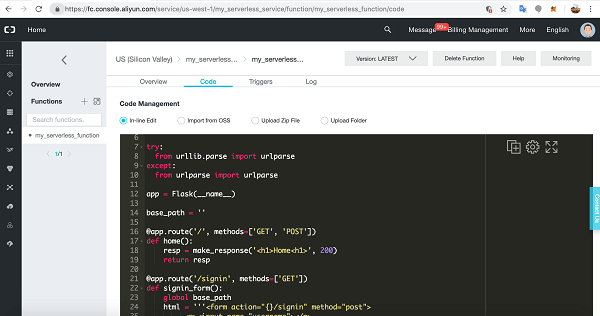
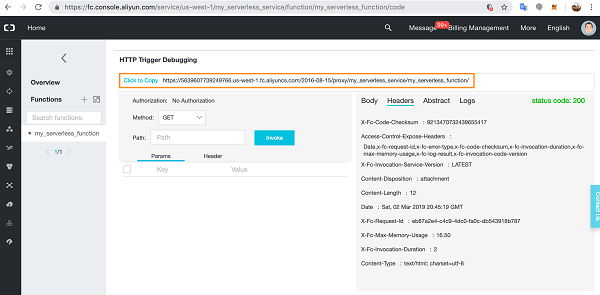
One of the major benefits of cloud computing is its ability to abstract (hide) the infrastructure layer. This ability eliminates the need to manually manage the underlying physical hardware. In a serverless environment, this abstraction allows you to focus on the code for your applications without spending time building and maintaining the underlying infrastructure. With serverless applications, there are never instances, operating systems, or servers to manage. AWS handles everything required to run and scale your application. By building serverless applications, your developers can focus on the code that makes your business unique.
Serverless operational tasks
| Deployment and Operational tasks | Traditional Environment | Serverless |
|---|---|---|
| Configure an instance | YES | – |
| Update operating system (OS) | YES | – |
| Install application platform | YES | – |
| Build and deploy apps | YES | YES |
| Configure automatic scaling and load balancing | YES | – |
| Continuously secure and monitor instances | YES | – |
| Monitor and maintain apps | YES | YES |
AWS serverless platform
The AWS serverless platform includes a number of fully managed services that are tightly integrated with AWS Lambda and well-suited for serverless applications. Developer tools, including the AWS Serverless Application Model (AWS SAM), help simplify deployment of your Lambda functions and serverless applications.

What is AWS Lambda?
AWS Lambda is a compute service. You can use it to run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure. It operates and maintains all of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging. With Lambda, you can run code for almost any type of application or backend service.
Some benefits of using Lambda include the following:
- You can run code without provisioning or maintaining servers.
- It initiates functions for you in response to events.
- It scales automatically.
- It provides built-in code monitoring and logging via Amazon CloudWatch
AWS Lambda features
Event-driven architectures
An event-driven architecture uses events to initiate actions and communication between decoupled services. An event is a change in state, a user request, or an update, like an item being placed in a shopping cart in an e-commerce website. When an event occurs, the information is published for other services to consume it. In event-driven architectures, events are the primary mechanism for sharing information across services. These events are observable, such as a new message in a log file, rather than directed, such as a command to specifically do something.
Producers, routers, consumers
AWS Lambda is an example of an event-driven architecture. Most AWS services generate events and act as an event source for Lambda. Lambda runs custom code (functions) in response to events. Lambda functions are designed to process these events and, once invoked, may initiate other actions or subsequent events.
What is a Lambda function?
The code you run on AWS Lambda is called a Lambda function. Think of a function as a small, self-contained application. After you create your Lambda function, it is ready to run as soon as it is initiated. Each function includes your code as well as some associated configuration information, including the function name and resource requirements. Lambda functions are stateless, with no affinity to the underlying infrastructure. Lambda can rapidly launch as many copies of the function as needed to scale to the rate of incoming events.
After you upload your code to AWS Lambda, you can configure an event source, such as an Amazon Simple Storage Service (Amazon S3) event, Amazon DynamoDB stream, Amazon Kinesis stream, or Amazon Simple Notification Service (Amazon SNS) notification. When the resource changes and an event is initiated, Lambda will run your function and manage the compute resources as needed to keep up with incoming requests.
How AWS Lambda Works
Invocation models for running Lambda functions
Event sources can invoke a Lambda function in three general patterns. These patterns are called invocation models. Each invocation model is unique and addresses a different application and developer needs. The invocation model you use for your Lambda function often depends on the event source you are using. It’s important to understand how each invocation model initializes functions and handles errors and retries.
Synchronous invocation
When you invoke a function synchronously, Lambda runs the function and waits for a response. When the function completes, Lambda returns the response from the function’s code with additional data, such as the version of the function that was invoked. Synchronous events expect an immediate response from the function invocation.
With this model, there are no built-in retries. You must manage your retry strategy within your application code.
The following AWS services invoke Lambda synchronously:
- Amazon API Gateway
- Amazon Cognito
- AWS CloudFormation
- Amazon Alexa
- Amazon Lex
- Amazon CloudFront
Asynchronous invocation
When you invoke a function asynchronously, events are queued and the requestor doesn’t wait for the function to complete. This model is appropriate when the client doesn’t need an immediate response.
With the asynchronous model, you can make use of destinations. Use destinations to send records of asynchronous invocations to other services.
The following AWS services invoke Lambda asynchronously:
- Amazon SNS
- Amazon S3
- Amazon EventBridge
Note :-
A destination can send records of asynchronous invocations to other services. You can configure separate destinations for events that fail processing and for events that process successfully. You can configure destinations on a function, a version, or an alias, similarly to how you can configure error handling settings. With destinations, you can address errors and successes without needing to write more code.
Polling invocation
This invocation model is designed to integrate with AWS streaming and queuing based services with no code or server management. Lambda will poll (or watch) these services, retrieve any matching events, and invoke your functions. This invocation model supports the following services:
- Amazon Kinesis
- Amazon SQS
- Amazon DynamoDB Streams
- Amazon MQ
- Amazon Managed Streaming for Apache Kafka (MSK)
- self-managed Apache Kafka
With this type of integration, AWS will manage the poller on your behalf and perform synchronous invocations of your function.
Invocation model error behavior
| Invocation model | Error behavior |
|---|---|
| Synchronous | No retries |
| Asynchronous | Built in – retries twice |
| Polling | Depends on event source |
Lambda execution environment
Lambda invokes your function in an execution environment, which is a secure and isolated environment. The execution environment manages the resources required to run your function. The execution environment also provides lifecycle support for the function’s runtime and any external extensions associated with your function.
Performance optimization
erverless applications can be extremely performant, thanks to the ease of parallelization and concurrency. While the Lambda service manages scaling automatically, you can optimize the individual Lambda functions used in your application to reduce latency and increase throughput.
Cold and warm starts
A cold start occurs when a new execution environment is required to run a Lambda function. When the Lambda service receives a request to run a function, the service first prepares an execution environment. During this step, the service downloads the code for the function, then creates the execution environment with the specified memory, runtime, and configuration. Once complete, Lambda runs any initialization code outside of the event handler before finally running the handler code.
In a warm start, the Lambda service retains the environment instead of destroying it immediately. This allows the function to run again within the same execution environment. This saves time by not needing to initialize the environment.
Best practice: Minimize cold start times
When you invoke a Lambda function, the invocation is routed to an execution environment to process the request. If the environment is not already initialized, the start-up time of the environment adds to latency. If a function has not been used for some time, if more concurrent invocations are required, or if you update a function, new environments are created. Creation of these environments can introduce latency for the invocations that are routed to a new environment. This latency is implied when using the term cold start. For most applications, this additional latency is not a problem. However, for some synchronous models, this latency can inhibit optimal performance. It is critical to understand latency requirements and try to optimize your function for peak performance.
After optimizing your function, another way to minimize cold starts is to use provisioned concurrency. Provisioned concurrency is a Lambda feature that prepares concurrent execution environments before invocations.
Best practice: Write functions to take advantage of warm starts
- Store and reference dependencies locally.
- Limit re-initialization of variables.
- Add code to check for and reuse existing connections.
- Use tmp space as transient cache.
- Check that background processes have completed.
Design best practices
- Separate business logic
- Write modular functions
- Treat functions as stateless
- Only include what you need
Best practices for writing code
- Include logging statements
- Use return coding
- Provide environment variables
- Add secret and reference data
- Avoid recursive code
- Gather metrics with Amazon CloudWatch
- Reuse execution context
Reference
AWS Lambda execution environment
Cheers
Osama