In this blog, we will explore how to build a scalable data pipeline on Oracle Cloud Infrastructure (OCI) using OCI Data Flow. We’ll cover the end-to-end process, from setting up OCI Data Flow to processing large datasets, and integrating with other OCI services.
Introduction to OCI Data Flow
- Overview of OCI Data Flow and its key features.
- Benefits of using a serverless, scalable data processing service.
- Common use cases for OCI Data Flow, including ETL, real-time analytics, and machine learning.
Setting Up OCI Data Flow
Prerequisites
- An active Oracle Cloud account.
- Necessary permissions and quotas for creating OCI resources.
Configuration Steps
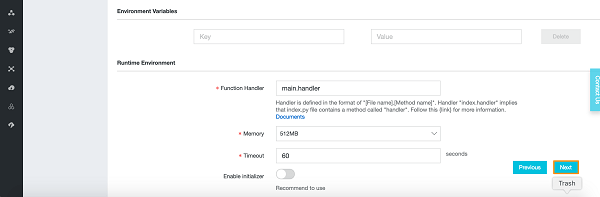
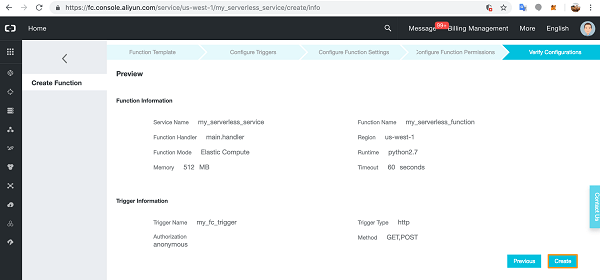
- Create a Data Flow Application:
- Navigate to the OCI Console and open the Data Flow service.
- Click on “Create Application” and provide the necessary details.
- Define your application’s parameters and Spark version.
- Configure Networking:
- Set up Virtual Cloud Network (VCN) and subnets.
- Ensure proper security lists and network security groups (NSGs) for secure communication.
3. Creating a Scalable Data Pipeline
Designing the Data Pipeline
- Outline the flow of data from source to target.
- Example pipeline: Ingest data from OCI Object Storage, process it using Data Flow, and store results in an Autonomous Database.
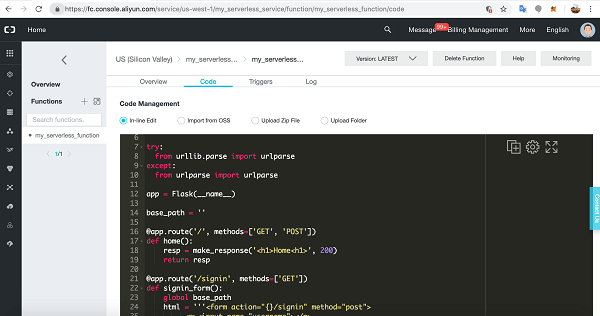
Developing Data Flow Jobs
- Write Spark jobs in Scala, Python, or Java.
- Example Spark job to process data:
val df = spark.read.json("oci://<bucket_name>@<namespace>/data/")
df.filter("age > 30").write.csv("oci://<bucket_name>@<namespace>/output/")
Deploying and Running Jobs
- Deploy the Spark job to OCI Data Flow.
- Schedule and manage job runs using OCI Console or CLI.
Processing Large Datasets
Handling Big Data
- Techniques for optimizing Spark jobs for large datasets.
- Using partitions and caching to improve performance.
Example: Processing a 1TB Dataset
- Step-by-step guide to ingest, process, and analyze a 1TB dataset using OCI Data Flow.
5. Integrating with Other OCI Services
OCI Object Storage
- Use Object Storage for data ingestion and storing intermediate results.
- Configure Data Flow to directly access Object Storage buckets.
OCI Autonomous Database
- Store processed data in an Autonomous Database.
- Example of loading data from Data Flow to Autonomous Database.
OCI Streaming
- Integrate with OCI Streaming for real-time data processing.
- Example: Stream processing pipeline using OCI Streaming and Data Flow.
Optimizing Data Flow Jobs
Performance Tuning
- Tips for optimizing resource usage and job execution times.
- Adjusting executor memory, cores, and dynamic allocation settings.
Cost Management
- Strategies for minimizing costs while running Data Flow jobs.
- Monitor job execution and cost metrics using the OCI Console.